阅读以下说明和Java代码,填补Java代码中的空缺(1)~(6),将解答写在答题纸的对应栏内。
【说明】
已知某公司按周给员工发放工资,其工资系统需记录每名员工的员工号、姓名、工资等信息。其中一些员工是正式的,按年薪分周发放(每年按52周计算);另一些员工是计时工,以小时工资为基准,按每周工作小时数核算发放。
下面是实现该工资系统的Java代码,其中定义了四个类:工资系统类PayRoll,员工类Employee,正式工类Salaried和计时工类Hourly,Salaried和Hourly是Employee的子类。
【Java代码】
abstract class Employee {
protected String name; //员工姓名
protected int empCode; //员工号
protected double salary; //周发放工资
public Employee(int empCode, String name) {
this.empCode=empCode;
this.name=name,
}
public double getSalary(){
return this.salary;
}
public abstract void pay() ;
}
class Salaried (1) Employee {
private double annualSalary;
Salaried(int empCode, String name, double payRate) {
super(empCode, name) ;
this.annualSalary=payRate;
}
public void pay () {
salary= (2) ; //计算正式员工的周发放工资数
System.out.println(this.name+":"+this.salary);
}
}
class Hourly (3) Employee {
private double hourlyPayRate;
private int hours;
Hourly(int empCode, String name, int hours, double payRate) {
super(empCode, name);
this.hourlyPayRate=payRate;
this.hours=hours;
}
public void pay () {
salary= (4) ; //计算计时工的周发放工资数
System.out.println(thisname+":"+this.salary);
}
}
public class PayRoll {
private (5) employees[]={
new Salaried(1001, "Zhang San", 58000.00),
//此处省略对其他职工对象的生成
new Hourly(1005, "Li", 12, 50.00)
};
public void pay(Employee e[]) {
for (int i=0; i
e[i]pay();
}
}
public static void main(String[] args)
{
PayRoll payRoll=new PayRoll();
payRoll.pay( (6) );
double total=0.0;
for (int i=0;i
total+=payRoll.employees[i].getSalary();
}
System.out.println(total);
}
}
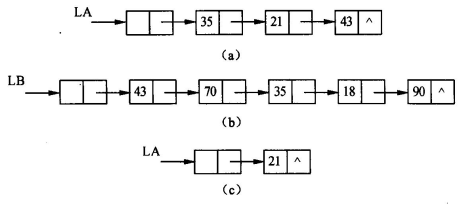

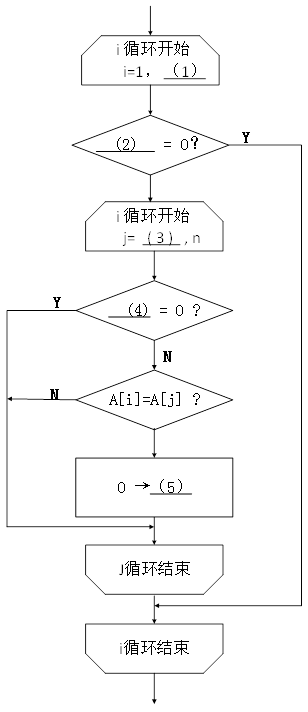
 【Java代码】
【Java代码】 【C++代码】
【C++代码】