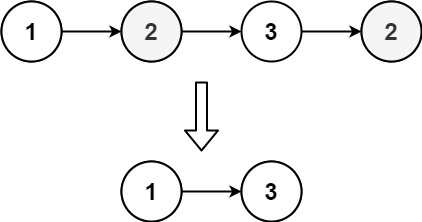
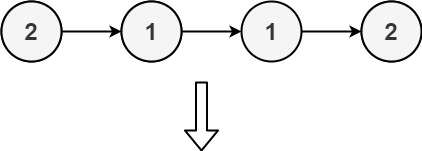
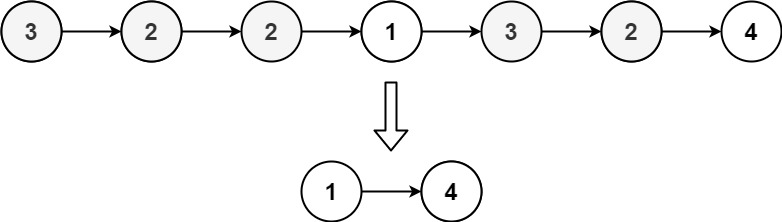
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func deleteDuplicatesUnsorted(head *ListNode) *ListNode {
var m = make(map[int]int)
for h:=head;h!=nil;h = h.Next{
m[h.Val]++
}
dummy := &ListNode{0,head}
pre := dummy
for h:=head;h!=nil;h = h.Next{
if m[h.Val]>1{
pre.Next = h.Next
}else{
pre = h
}
}
return dummy.Next
}
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def deleteDuplicatesUnsorted(self, head: ListNode) -> ListNode:
b = ListNode(0, head)
d = {}
p = head
# 第一次遍历,查出重复的节点,
while p:
if p.val not in d:
d[p.val] = 1
b = b.next
else:
d[p.val] +=1
b.next = b = p.next
p = p.next
w = pr = ListNode(0, head)
while head:
if d[head.val] > 1:
pr.next = head.next
else:
pr = pr.next
head = head.next
return w.next
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def deleteDuplicatesUnsorted(self, head: ListNode) -> ListNode:
dup = set()
pre = set()
cur = head
while cur:
if cur.val in pre:
dup.add(cur.val)
pre.add(cur.val)
cur = cur.next
ans = ListNode(-1) # 哨兵节点
node = ans
while head:
if head.val not in dup:
tmp = head.next
head.next = None
node.next = head
node = node.next
head = tmp
else:
head = head.next
return ans.next