
参考答案:
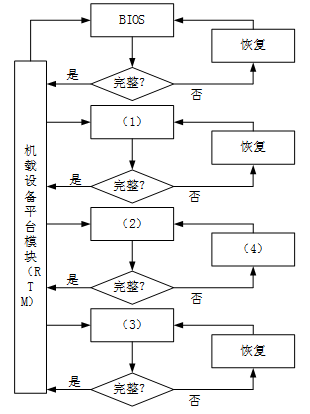
【问题1】 (1)OSLoader (2)操作系统 (3)应用 (4)恢复
带数据恢复星型信任模型的特点:
(1)可信测量根被保护,安全性更高。
(2)具有数据恢复功能,安全性更高。
(3)都是一级测量,没有多级信任传递,信任损失少。
【问题2】
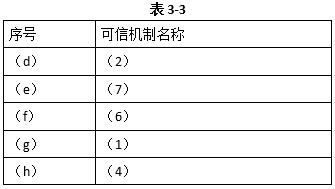
(见表3-2、表3-3所示)
详细解析:
可信计算的基本思想是:首先在计算机系统中建立一个信任根,再建立一条信任链,从信任根开始,经过硬件平台和操作系统,再到应用,一级测量认证一级,一级信任一级,从而把这种信任扩展到整个计算机系统。
【问题1】
可信计算组织的信任链采用了一种链式的信任测量模型,即由RTM(可信测量根)→BIOS→OSLoader→OS构成一个串行链。由于采用了一种迭代计算哈希值的方式,即将现值与新值相连,再计算哈希值并作为新的完整性度量值存储起来。
链式信任链具有如下缺点:信任链越长,信任损失的可能性就越大。在链中加入或删除一个部件,PCR的值需要重新计算,很麻烦。信任链中的软件部件可能会更新(如BIOS升级,OS打补丁等),而PCR的值也得重新计算,这样一来使得部件更新工作很麻烦。
带数据恢复的星型信任模型结构如图3-3所示。
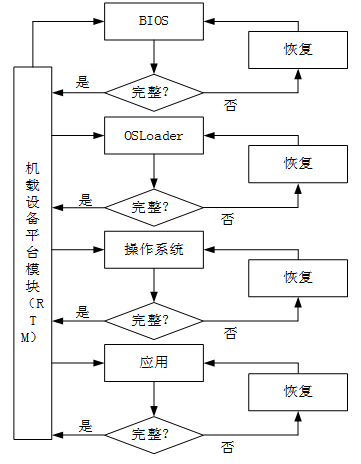
图3-3
它将可信测量根置入可信平台模块内部NVRAM (Non-VolatileRandom Access Memory,非易失性随机访问存储器),在信任链中增加了数据恢复功能,并将信任链延伸到应用。与可信计算组织的链式信任链相比,该模型具有如下特点:可信测量根被保护,安全性更高;具有数据恢复功能,安全性更高;都是一级测量,没有多级信任传递,信任损失少。但是,所有测量都由可信测量根执行,可信测量根通过可信平台模块完成任务,这使得可信平台模块负担加重。
在可信计算的信任链中应当度量的是可信性。但是,由于可信性目前尚不易直接度量,所以可信计算组织在信任链中采用的是度量数据完整性,而且是通过校验数据哈希值的方法来度量数据的完整性。但是,可信≈可靠+安全,完整性≠可信性,完整性 可信性,即完整性只是可信性中的一个侧面。
由于可信计算组织在信任链中采用的是度量数据完整性,因此它能确保数据的完整性,确保BIOS,OSLoader和OS数据的完整性。但是完整性只能说明这些软件没有被修改,并不能说明这些软件没有安全缺陷,更不能确保这些软件在运行时的安全性。基于数据完整性的度量是一种静态度量,基于软件行为的动态度量更实用。
【问题2】
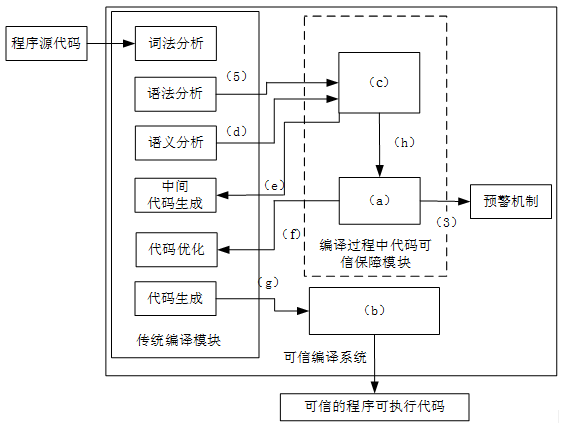
编译器作为重要的系统软件,其可信性对于整个计算机系统的可信具有重要意义。如果编译器不可信,则很难保证其他软件的可信性。软件的可信性很大程度上依赖于程序代码的可信性,影响软件可信性的主要因素包括来自软件内部的代码缺陷、代码错误、程序故障以及来自软件外部的病毒、恶意代码等。因此,从代码角度来保证软件的可信性是实现可信软件的重要途径之一。
可信编译的目标就是从编译的角度保证软件的可信性,主要包括两方面含义,一方面,必须保证编译器自身是可信的。即必须保证整个编译操作的可信性,保证编译器在编译过程中不会给编译处理对象带来任何安全性问题,防止恶意攻击者通过修改编译器,在编译过程中对代码的原始语义进行篡改,影响程序代码本身的可信性;另一方面,必须保证编译器编译所得程序可执行代码是可信的,即编译器必须保证,通过其编译生成的程序代码是安全和可靠的。
编译器自身的可信性主要是指其编译过程的正确性、安全性和可靠性。一般认为,通过形式化验证的系统具有较高的可信性,可将形式化方法用于编译器本身。通过在传统编译操作的基础下加入代码安全性加强机制、代码可信性验证机制及可执行代码保护机制等三种机制,来保证编译所产生代码的可信性。
(1)代码安全性加强机制:该机制主要用于识别和处理程序中常见的一些安全漏洞。目前已提出许多针对程序常见安全漏洞的编译处理技术,具有代表性的如针对缓冲区溢出攻击的StackGuard方法等。
(2)代码可信性验证:该机制不可能解决所有的代码安全性问题。对于可信性要求较高的程序代码,必须通过形式化方法对其进行可信性验证。因此,我们提出在代码安全性加强机制对代码进行安全加强之后,通过代码可信性验证机制对代码的可信属性进行验证,对未通过验证的非可信代码进行报警或其他处理。这样,通过代码安全性加强和可信性验证相结合的方法保证编译生成可执行代码的可信性。
(3)可执行代码保护机制:为了防止攻击者对可信编译器最终生成的可执行代码进行恶意攻击或修改,可信编译器在完成编译之后,对可执行代码实施保护机制,保护编译所得可执行代码的完整性、秘密性和可用性,从而确保系统最终执行代码的可信运行。