参考答案:
【问题1】
GFS与HDFS相比的相同点是:单一控制机和多台工作机;通过数据分块和复制实现可靠性和高性能;树状文件系统结构;
GFS与HDFS相比的不同点是:多次写入和多客户端并发增加数据;Master单点失效问题;数据快照的支持;实时性支持。
针对系统需求,文档协作要求多客户端并发写入文件支持;解决主服务器单点失效问题;系统补偿操作需要数据快照。
【问题2】
读数据过程:
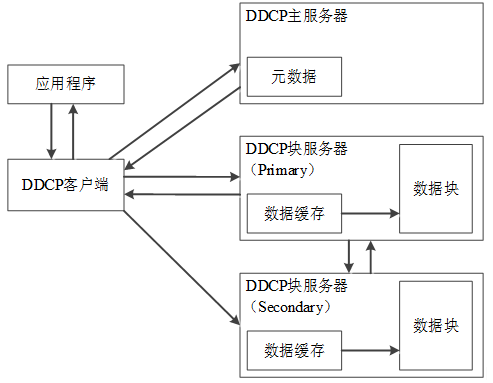
1. 应用程序将读数据请求发送给DDCP客户端;
2. DDCP客户端访问DDCP主服务器请求所需数据位置信息;
3. DDCP主服务器查询数据分块和地址信息发送给DDCP客户端;
4. DDCP客户端根据地址信息向DDCP块服务器发送读数据请求;
5. DDCP块服务器将所请求数据发送给DDCP客户端;
6. DDCP客户端将数据转发给应用程序。
并发写数据过程:
1.并发写的应用程序分别将数据和写数据请求发送给DDCP客户端;
2. DDCP客户端依次访问DDCP主服务器请求所写数据位置信息;
3. DDCP主服务器依次查询数据分块和地址信息发送给DDCP客户端;
4. DDCP客户端将所要写入的数据重新组织,将属于同一个DDCP块服务器的数据按照分组报文和分组序列信息发送给DDCP块服务器数据缓存(Primary);
5. DDCP客户端将所写数据按照分组报文发送给DDCP块服务器数据缓存(Secondary);
6. DDCP块服务器数据缓存(Primary)按照分组序列将数据写入到DDCP块服务器数据块(Primary);
7. DDCP块服务器(Primary)将分组序列发送给DDCP块服务器(Secondary);
8. DDCP块服务器数据缓存(Secondary)按照分组序列将数据写入DDCP块服务器数据块(Secondary);
9. DDCP块服务器(Secondary)将写入完成信息发送给DDCP块服务器(Primary);
10. DDCP块服务器数据(Primary)将写数据完成信息发送给DDCP客户端。
【问题3】
GFS中采用主从模式备份Master的系统元数据,当主Master失效时,可以通过分布式选举备机接替主Master继续对外提供服务,而由于复制及主备切换本身有一定的复杂性,HDFS Master的持久化数据只写入到本机(可能写入多份存放到Master机器的多个磁盘中防止某个磁盘损害),出现故障时需要人工介入。
详细解析:
分布式数据存储系统是实现云计算和面向服务计算等分布式计算模型的基础,采用不同的分布式文件系统架构决定了分布式数据存储系统的运行效率、可伸缩性、容错能力及安全性等。分布式文件系统是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连,从而实现了数据的分布式存储和管理。Google的GFS文件系统和Hadoop分布式文件系统HDFS是当前最流行的两种分布式文件系统参考架构。
本题主要考查应试者对于分布式文件系统设计的掌握情况,特别是GFS和HDFS分布式文件系统架构的设计。本题结合一个典型的实际项目案例,首先要求分析GFS和HDFS之间的异同,然后针对系统需求分析采用GFS文件系统的原因;针对项目中所设计的DDCP基础架构,分析数据读写操作的过程;最后针对具体的单点失效问题,说明两种分布式文件系统架构所提供的解决方案。
【问题1】
本题要求考生针对GFS和HDFS两种分布式文件系统架构的特点展开分析并进行总结。
(1)GFS是一个面向大规模数据密集型应用的、可伸缩的分布式文件系统,虽然运行在多台普通硬件设备上,但是它提供了灾难冗余的能力,为大量客户机提供高性能的服务。一个GFS集群中包含了一个单独的Master节点、多台Chunk服务器,并且同时被多个客户端访问。GFS存储的文件被分割为固定大小的Chunk并分配标识,缺省提供3个存储复制节点,Master节点管理所有的文件系统元数据,GFS客户端代码以库的形式被链接到客户程序里,无论是客户端还是Chunk服务器都不需要缓存文件数据。
(2)HDFS是一个高度容错性的系统,能够提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS采用Master/Slave架构,一个HDFS集群由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的命名空间以及客户端对文件的访问,集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。一个文件被分成一个或多个数据块,这些块存储在一组Datanode上,Namenode执行文件系统的命名空间操作并确定数据块到具体Datanode节点的映射,Datanode在Namenode的统一调度下负责处理文件系统客户端的读写请求。
【问题2】
本题要求考生认真分析图中给出的DDCP系统架构,依据图中节点之间的数据传输关系描述数据传输过程。
(1)读数据的过程:应用程序将读数据请求发送给客户端后,客户端访问主服务器请求所需数据位置信息,主服务器查询数据分块和地址信息返回给客户端,客户端根据地址信息向块服务器发送读数据请求,块服务器将所请求数据发送给客户端,客户端将数据转发给应用程序。
(2)写数据的过程:应用程序分别将数据和写数据请求发送给客户端,客户端依次访问主服务器请求所写数据位置信息,主服务器依次查询数据分块和地址信息发送给客户端,客户端将所要写入的数据重新组织,将属于同一个块服务器的数据按照分组报文和分组序列信息发送给块服务器数据缓存(Primary),客户端将所写数据按照分组报文发送给块服务器数据缓存(Secondary),块服务器数据缓存(Primary)按照分组序列将数据写入到块服务器数据块(Primary),块服务器(Primary)将分组序列发送给块服务器(Secondary),块服务器数据缓存(Secondary)按照分组序列将数据写入块服务器数据块(Secondary),块服务器(Secondary)将写入完成信息发送给块服务器(Primary),块服务器数据(Primary)将写数据完成信息发送给客户端。
【问题3】
本题要求应试者掌握单点失效问题产生的原因,并能够结合GFS和HDFS架构的特点进行分析,说明所采用的解决方案。