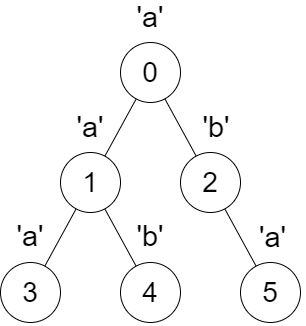
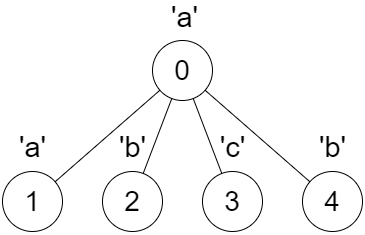
上次编辑到这里,代码来自缓存 点击恢复默认模板
class Solution {
public:
vector<bool> findAnswer(vector<int>& parent, string s) {
}
};
golang 解法, 执行用时: 197 ms, 内存消耗: 40.4 MB, 提交时间: 2024-11-09 00:05:22
func findAnswer(parent []int, s string) []bool {
n := len(parent)
g := make([][]int, n)
for i := 1; i < n; i++ {
p := parent[i]
// 由于 i 是递增的,所以 g[p] 必然是有序的,下面无需排序
g[p] = append(g[p], i)
}
// dfsStr 是后序遍历整棵树得到的字符串
dfsStr := make([]byte, n)
// nodes[i] 表示子树 i 的后序遍历的开始时间戳和结束时间戳+1(左闭右开区间)
nodes := make([]struct{ begin, end int }, n)
time := 0
var dfs func(int)
dfs = func(x int) {
nodes[x].begin = time
for _, y := range g[x] {
dfs(y)
}
dfsStr[time] = s[x] // 后序遍历
time++
nodes[x].end = time
}
dfs(0)
// Manacher 模板
// 将 dfsStr 改造为 t,这样就不需要讨论 n 的奇偶性,因为新串 t 的每个回文子串都是奇回文串(都有回文中心)
// dfsStr 和 t 的下标转换关系:
// (dfsStr_i+1)*2 = ti
// ti/2-1 = dfsStr_i
// ti 为偶数,对应奇回文串(从 2 开始)
// ti 为奇数,对应偶回文串(从 3 开始)
t := append(make([]byte, 0, n*2+3), '^')
for _, c := range dfsStr {
t = append(t, '#', c)
}
t = append(t, '#', '$')
// 定义一个奇回文串的回文半径=(长度+1)/2,即保留回文中心,去掉一侧后的剩余字符串的长度
// halfLen[i] 表示在 t 上的以 t[i] 为回文中心的最长回文子串的回文半径
// 即 [i-halfLen[i]+1,i+halfLen[i]-1] 是 t 上的一个回文子串
halfLen := make([]int, len(t)-2)
halfLen[1] = 1
// boxR 表示当前右边界下标最大的回文子串的右边界下标+1
// boxM 为该回文子串的中心位置,二者的关系为 r=mid+halfLen[mid]
boxM, boxR := 0, 0
for i := 2; i < len(halfLen); i++ { // 循环的起止位置对应着原串的首尾字符
hl := 1
if i < boxR {
// 记 i 关于 boxM 的对称位置 i'=boxM*2-i
// 若以 i' 为中心的最长回文子串范围超出了以 boxM 为中心的回文串的范围(即 i+halfLen[i'] >= boxR)
// 则 halfLen[i] 应先初始化为已知的回文半径 boxR-i,然后再继续暴力匹配
// 否则 halfLen[i] 与 halfLen[i'] 相等
hl = min(halfLen[boxM*2-i], boxR-i)
}
// 暴力扩展
// 算法的复杂度取决于这部分执行的次数
// 由于扩展之后 boxR 必然会更新(右移),且扩展的的次数就是 boxR 右移的次数
// 因此算法的复杂度 = O(len(t)) = O(n)
for t[i-hl] == t[i+hl] {
hl++
boxM, boxR = i, i+hl
}
halfLen[i] = hl
}
// t 中回文子串的长度为 hl*2-1
// 由于其中 # 的数量总是比字母的数量多 1
// 因此其在 dfsStr 中对应的回文子串的长度为 hl-1
// 这一结论可用在 isPalindrome 中
// 判断左闭右开区间 [l,r) 是否为回文串 0<=l<r<=n
// 根据下标转换关系得到 dfsStr 的 [l,r) 子串在 t 中对应的回文中心下标为 l+r+1
// 需要满足 halfLen[l+r+1]-1 >= r-l,即 halfLen[l+r+1] > r-l
isPalindrome := func(l, r int) bool { return halfLen[l+r+1] > r-l }
ans := make([]bool, n)
for i, p := range nodes {
ans[i] = isPalindrome(p.begin, p.end)
}
return ans
}
python3 解法, 执行用时: 2852 ms, 内存消耗: 71.7 MB, 提交时间: 2024-11-09 00:05:00
class Solution:
def findAnswer(self, parent: List[int], s: str) -> List[bool]:
n = len(parent)
g = [[] for _ in range(n)]
for i in range(1, n):
p = parent[i]
# 由于 i 是递增的,所以 g[p] 必然是有序的,下面无需排序
g[p].append(i)
# dfsStr 是后序遍历整棵树得到的字符串
dfsStr = [''] * n
# nodes[i] 表示子树 i 的后序遍历的开始时间戳和结束时间戳+1(左闭右开区间)
nodes = [[0, 0] for _ in range(n)]
time = 0
def dfs(x: int) -> None:
nonlocal time
nodes[x][0] = time
for y in g[x]:
dfs(y)
dfsStr[time] = s[x] # 后序遍历
time += 1
nodes[x][1] = time
dfs(0)
# Manacher 模板
# 将 dfsStr 改造为 t,这样就不需要讨论 n 的奇偶性,因为新串 t 的每个回文子串都是奇回文串(都有回文中心)
# dfsStr 和 t 的下标转换关系:
# (dfsStr_i+1)*2 = ti
# ti/2-1 = dfsStr_i
# ti 为偶数,对应奇回文串(从 2 开始)
# ti 为奇数,对应偶回文串(从 3 开始)
t = '#'.join(['^'] + dfsStr + ['$'])
# 定义一个奇回文串的回文半径=(长度+1)/2,即保留回文中心,去掉一侧后的剩余字符串的长度
# halfLen[i] 表示在 t 上的以 t[i] 为回文中心的最长回文子串的回文半径
# 即 [i-halfLen[i]+1,i+halfLen[i]-1] 是 t 上的一个回文子串
halfLen = [0] * (len(t) - 2)
halfLen[1] = 1
# boxR 表示当前右边界下标最大的回文子串的右边界下标+1
# boxM 为该回文子串的中心位置,二者的关系为 r=mid+halfLen[mid]
boxM = boxR = 0
for i in range(2, len(halfLen)):
hl = 1
if i < boxR:
# 记 i 关于 boxM 的对称位置 i'=boxM*2-i
# 若以 i' 为中心的最长回文子串范围超出了以 boxM 为中心的回文串的范围(即 i+halfLen[i'] >= boxR)
# 则 halfLen[i] 应先初始化为已知的回文半径 boxR-i,然后再继续暴力匹配
# 否则 halfLen[i] 与 halfLen[i'] 相等
hl = min(halfLen[boxM * 2 - i], boxR - i)
# 暴力扩展
# 算法的复杂度取决于这部分执行的次数
# 由于扩展之后 boxR 必然会更新(右移),且扩展的的次数就是 boxR 右移的次数
# 因此算法的复杂度 = O(len(t)) = O(n)
while t[i - hl] == t[i + hl]:
hl += 1
boxM, boxR = i, i + hl
halfLen[i] = hl
# t 中回文子串的长度为 hl*2-1
# 由于其中 # 的数量总是比字母的数量多 1
# 因此其在 dfsStr 中对应的回文子串的长度为 hl-1
# 这一结论可用在 isPalindrome 中
# 判断左闭右开区间 [l,r) 是否为回文串 0<=l<r<=n
# 根据下标转换关系得到 dfsStr 的 [l,r) 子串在 t 中对应的回文中心下标为 l+r+1
# 需要满足 halfLen[l + r + 1] - 1 >= r - l,即 halfLen[l + r + 1] > r - l
def isPalindrome(l: int, r: int) -> bool:
return halfLen[l + r + 1] > r - l
return [isPalindrome(l, r) for l, r in nodes]
java 解法, 执行用时: 399 ms, 内存消耗: 100.5 MB, 提交时间: 2024-11-09 00:04:46
class Solution {
private int time = 0;
public boolean[] findAnswer(int[] parent, String s) {
int n = parent.length;
List<Integer>[] g = new ArrayList[n];
Arrays.setAll(g, i -> new ArrayList<>());
for (int i = 1; i < n; i++) {
int p = parent[i];
// 由于 i 是递增的,所以 g[p] 必然是有序的,下面无需排序
g[p].add(i);
}
// dfsStr 是后序遍历整棵树得到的字符串
char[] dfsStr = new char[n];
// nodes[i] 表示子树 i 的后序遍历的开始时间戳和结束时间戳+1(左闭右开区间)
int[][] nodes = new int[n][2];
dfs(0, g, s.toCharArray(), dfsStr, nodes);
// Manacher 模板
// 将 dfsStr 改造为 t,这样就不需要讨论 n 的奇偶性,因为新串 t 的每个回文子串都是奇回文串(都有回文中心)
// dfsStr 和 t 的下标转换关系:
// (dfsStr_i+1)*2 = ti
// ti/2-1 = dfsStr_i
// ti 为偶数,对应奇回文串(从 2 开始)
// ti 为奇数,对应偶回文串(从 3 开始)
char[] t = new char[n * 2 + 3];
Arrays.fill(t, '#');
t[0] = '^';
for (int i = 0; i < n; i++) {
t[i * 2 + 2] = dfsStr[i];
}
t[n * 2 + 2] = '$';
// 定义一个奇回文串的回文半径=(长度+1)/2,即保留回文中心,去掉一侧后的剩余字符串的长度
// halfLen[i] 表示在 t 上的以 t[i] 为回文中心的最长回文子串的回文半径
// 即 [i-halfLen[i]+1,i+halfLen[i]-1] 是 t 上的一个回文子串
int[] halfLen = new int[t.length - 2];
halfLen[1] = 1;
// boxR 表示当前右边界下标最大的回文子串的右边界下标+1
// boxM 为该回文子串的中心位置,二者的关系为 r=mid+halfLen[mid]
int boxM = 0;
int boxR = 0;
for (int i = 2; i < halfLen.length; i++) { // 循环的起止位置对应着原串的首尾字符
int hl = 1;
if (i < boxR) {
// 记 i 关于 boxM 的对称位置 i'=boxM*2-i
// 若以 i' 为中心的最长回文子串范围超出了以 boxM 为中心的回文串的范围(即 i+halfLen[i'] >= boxR)
// 则 halfLen[i] 应先初始化为已知的回文半径 boxR-i,然后再继续暴力匹配
// 否则 halfLen[i] 与 halfLen[i'] 相等
hl = Math.min(halfLen[boxM * 2 - i], boxR - i);
}
// 暴力扩展
// 算法的复杂度取决于这部分执行的次数
// 由于扩展之后 boxR 必然会更新(右移),且扩展的的次数就是 boxR 右移的次数
// 因此算法的复杂度 = O(len(t)) = O(n)
while (t[i - hl] == t[i + hl]) {
hl++;
boxM = i;
boxR = i + hl;
}
halfLen[i] = hl;
}
// t 中回文子串的长度为 hl*2-1
// 由于其中 # 的数量总是比字母的数量多 1
// 因此其在 dfsStr 中对应的回文子串的长度为 hl-1
// 这一结论可用在下面的判断回文串中
boolean[] ans = new boolean[n];
for (int i = 0; i < n; i++) {
// 判断左闭右开区间 [l,r) 是否为回文串 0<=l<r<=n
// 根据下标转换关系得到 dfsStr 的 [l,r) 子串在 t 中对应的回文中心下标为 l+r+1
// 需要满足 halfLen[l + r + 1] - 1 >= r - l,即 halfLen[l + r + 1] > r - l
int l = nodes[i][0];
int r = nodes[i][1];
ans[i] = halfLen[l + r + 1] > r - l;
}
return ans;
}
private void dfs(int x, List<Integer>[] g, char[] s, char[] dfsStr, int[][] nodes) {
nodes[x][0] = time;
for (int y : g[x]) {
dfs(y, g, s, dfsStr, nodes);
}
dfsStr[time++] = s[x]; // 后序遍历
nodes[x][1] = time;
}
}