# Write your MySQL query statement below
1322. 广告效果
表: Ads
+---------------+---------+
| Column Name | Type |
+---------------+---------+
| ad_id | int |
| user_id | int |
| action | enum |
+---------------+---------+
(ad_id, user_id) 是该表的主键(具有唯一值的列的组合)
该表的每一行包含一条广告的 ID(ad_id),用户的 ID(user_id) 和用户对广告采取的行为 (action)
action 列是一个枚举类型 ('Clicked', 'Viewed', 'Ignored') 。
一家公司正在运营这些广告并想计算每条广告的效果。
广告效果用点击通过率(Click-Through Rate:CTR)来衡量,公式如下:
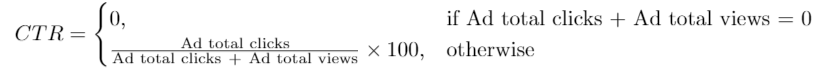
编写解决方案找出每一条广告的 ctr ,ctr 要 保留两位小数 。
返回结果需要按 ctr 降序、按 ad_id 升序 进行排序。
返回结果示例如下:
示例 1:
输入: Ads 表: +-------+---------+---------+ | ad_id | user_id | action | +-------+---------+---------+ | 1 | 1 | Clicked | | 2 | 2 | Clicked | | 3 | 3 | Viewed | | 5 | 5 | Ignored | | 1 | 7 | Ignored | | 2 | 7 | Viewed | | 3 | 5 | Clicked | | 1 | 4 | Viewed | | 2 | 11 | Viewed | | 1 | 2 | Clicked | +-------+---------+---------+ 输出: +-------+-------+ | ad_id | ctr | +-------+-------+ | 1 | 66.67 | | 3 | 50.00 | | 2 | 33.33 | | 5 | 0.00 | +-------+-------+ 解释: 对于 ad_id = 1, ctr = (2/(2+1)) * 100 = 66.67 对于 ad_id = 2, ctr = (1/(1+2)) * 100 = 33.33 对于 ad_id = 3, ctr = (1/(1+1)) * 100 = 50.00 对于 ad_id = 5, ctr = 0.00, 注意 ad_id = 5 没有被点击 (Clicked) 或查看 (Viewed) 过 注意我们不关心 action 为 Ingnored 的广告
原站题解